
Here are some demo HTML:
<html><body> <h1>Lorem ipsum dolor sit amet</h1> <p id="p1">Lorem ipsum dolor sit amet, consectetur adipiscing elit. <a href="blah.html" title="Cras massa purus">Cras massa purus</a>, euismod non dui eget, ullamcorper consequat augue. Fusce enim sem, suscipit a nulla quis, vestibulum fermentum nulla.</p> <p id="p2">Phasellus aliquam ligula id metus pellentesque ultrices. Ut aliquam nulla ante, vitae ultricies dui rutrum quis. <a href="blah.html" title="Suspendisse potenti">Suspendisse potenti</a>. Nunc eu hendrerit ex.</p> </body></html>
Example 1: raw XPath
/html/body/h1
Example 2: find an element by ID
//*[@id="p1"]
Example 3: child of Element ID
//*[@id="p1"]/a
or
//a[parent::*[@id="p1"]]
Example 4: find element contains a part of text
//p[contains(.,"dolor sit")]
Example 5: find element whose container is match with a text
//h1[.="Lorem ipsum dolor sit amet"]
or
//h1[ text()="Lorem ipsum dolor sit amet"]
Example 6: find element by one or some attribute
//a[@title="Cras massa purus"]
other:
//a[@title="Cras massa purus"][@href="blah.html"]
or
//a[@title="Cras massa purus" and @href="blah.html"]
other example with not:
//a[not(@title="Cras massa purus")]
or
//a[@title!="Cras massa purus"]
other example with or:
//a[@title="Cras massa purus" or @title="Suspendisse potenti"]
or
/html//a[@title="Cras massa purus" or @title="Suspendisse potenti"]
or
html//a[@title="Cras massa purus" or @title="Suspendisse potenti"]
Example 6: find element by child
//body[h1="Lorem ipsum dolor sit amet"]
other:
//p[a[@title="Cras massa purus"]]
Example 7: the Nth element
//a[1]
or
//a[position()=1]
or
//a[last()]
or
//a[position()=last()]
Result: 2 elements < a >
Other:
(//a)[2]
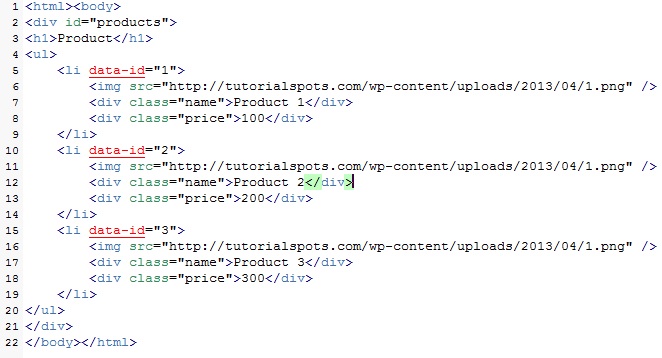
<html><body>
<div id="products">
<h1>Product</h1>
<ul>
<li data-id="1">
<img src="http://tutorialspots.com/wp-content/uploads/2013/04/1.png" />
<div class="name">Product 1</div>
<div class="price">100</div>
</li>
<li data-id="2">
<img src="http://tutorialspots.com/wp-content/uploads/2013/04/1.png" />
<div class="name">Product 2</div>
<div class="price">200</div>
</li>
<li data-id="3">
<img src="http://tutorialspots.com/wp-content/uploads/2013/04/1.png" />
<div class="name">Product 3</div>
<div class="price">300</div>
</li>
</ul>
</div>
</body></html>
Example 8:
//li[position() >= 2]
Return 2 elements < li >
Example 9:
//li[*="Product 1"]
Return all li elements containing any child element whose value is “Product 1”.
Example 10:
//div[@class="name" and ../div[@class="price"]>200]
Return all div elements whose attribute class is “name” and sibling element div whose attribute class is “price” and whose container is greater than 200.
End: You can use with Union “|” ex:
//li[*="Product 1"]|//div[@class="name" and ../div[@class="price"]>200]




1 Comment
Scraping web content by using YQL | Free Online Tutorials
(December 14, 2016 - 8:45 am)[…] Read first: HTML XPath examples […]